


"Inter-face" is something "between" two or many systems. It's what allows us to face each other.
Work, with a big W, is mostly about moving data from one interface to another.
This becomes even more complicated in the data industry, where connecting to various data sources and destinations remains a challenge. There's no perfect protocol-level solution yet.
The concept of "headless" isn't really new for experienced developers: the separation of the backend and frontend is already well-known in the field.
But sometimes new words carry the semantics to a broader audience and level. "Headless" is probably one of them.
As a concept, it accounts for applications that are not polarized toward one interface or another.
Headless systems have missions to let anyone interact with the “higher-end” interface they prefer. Keeping everyone focused in their favorite bubble while streamlining processes on the same occasion.
Strapi (headless CMS), Cube (headless BI), or Shopify (headless e-commerce) are great examples of headless products. LLMs, in some sense, are lossy headless interfaces for the Internet.
What's the best interface?
It's actually something I already discussed in the past.
But spoiler: there is no best interface.
To unfold our craft, we should design systems without human interface in mind. Instead: computer interface. Perhaps the future lies not in finding the "best" interface, but in creating adaptable systems that can seamlessly adjust to user preferences.
📡 Expected Contents
Apache Beam: YAML
I used to work with GCP Dataflow, the managed version of Apache Beam over Google Cloud.
It was powerful as a computing power but quite limited in terms of codebase maintenance. The SDK was complex to navigate and we could feel the lock-in in our custom logic easily1.
It's great to see an update on this project that can unify batch and streaming data processing.
Definitely circling back to the YAML Engineering pattern pushing everywhere in the stack recently.
Looking forward to seeing more proper use cases with this new semantic 👀

Bun, the killer of Node.js?
Every year (month?) someone announces the death of some Javascript framework - being frontend or backend...
Bun is a "fast JavaScript all-in-one toolkit" aiming to improve Node runtime built with
The javascript world is weird but this one could be worth looking for new projects.
My two cents: it's for the good. We built a lot of tools on top of the power of the Moore law without optimizing anything and building robust software. The momentum around Rust & co sounds like we're a bit more “responsible” nowadays. In the end, it will be great for the user interface. For our cognition.
Pivot table in Rill
I'm planning to invest more in Rill in the coming weeks at work. Having the opportunity to write my BI as code is definitely a fresher. It makes me much more confident in the data exposed.
Rill introduce Pivot table - a keystone for any Excel aficionados!
Like the other features already present, this one is working beautifully. Can't wait to have my analytics stuff in there!

Do you model in dbt or BI?
I heard about Omni quite recently during a nice meetup here in Paris.
The team is made of ex-Googler and his really friendly.
Though close-sourced, the product is great and is worth taking a look.
In this recent post, they ask one question every analytics engineer is asking: do we model in the warehouse or in the dashboard tool? Do we model in dbt or BI?
[...] when people ask “dbt or BI?”, they already know about the technical tradeoffs and are really asking about architecture: should dbt be the only interface between my data and my BI tool? Should I shove a dbt model in front of every table, just to keep the interface entirely in dbt?
As a software engineer, I find something appealing about this idea: well-defined interfaces are good, portability is good, and pulling all logic into dbt accomplishes both.
But…well-defined interfaces are only good if they are stable — i.e. they don’t change much — and this is where the strategy breaks down.
The interface of any real, actively used data set constantly changes: fields are being added or removed and relationships are changing. And if you build and update a dbt model every time your data or analysis changes, rather than just modifying the query in your BI tool, the work adds up.
"The interface of any real, actively used data set constantly changes"
This specific caught me up! Resonates a lot with today's intro.

📰 The Blog Post
The Data Team Equation: Balancing Staffing with Provisioning

I've matured a lot lately about how data teams are built and the typical problems they run into.Long story short, the core issue is often the disconnect between staffing and provisioning strategies.I believe there are some hints we can use to crack this 👀 Curious to hear your thoughts on this!
🎨 Beyond The Bracket

We're talking about data every day. We see them as the best proxy for reality.
But sometimes proxies are just proxies. And they can be tricked.
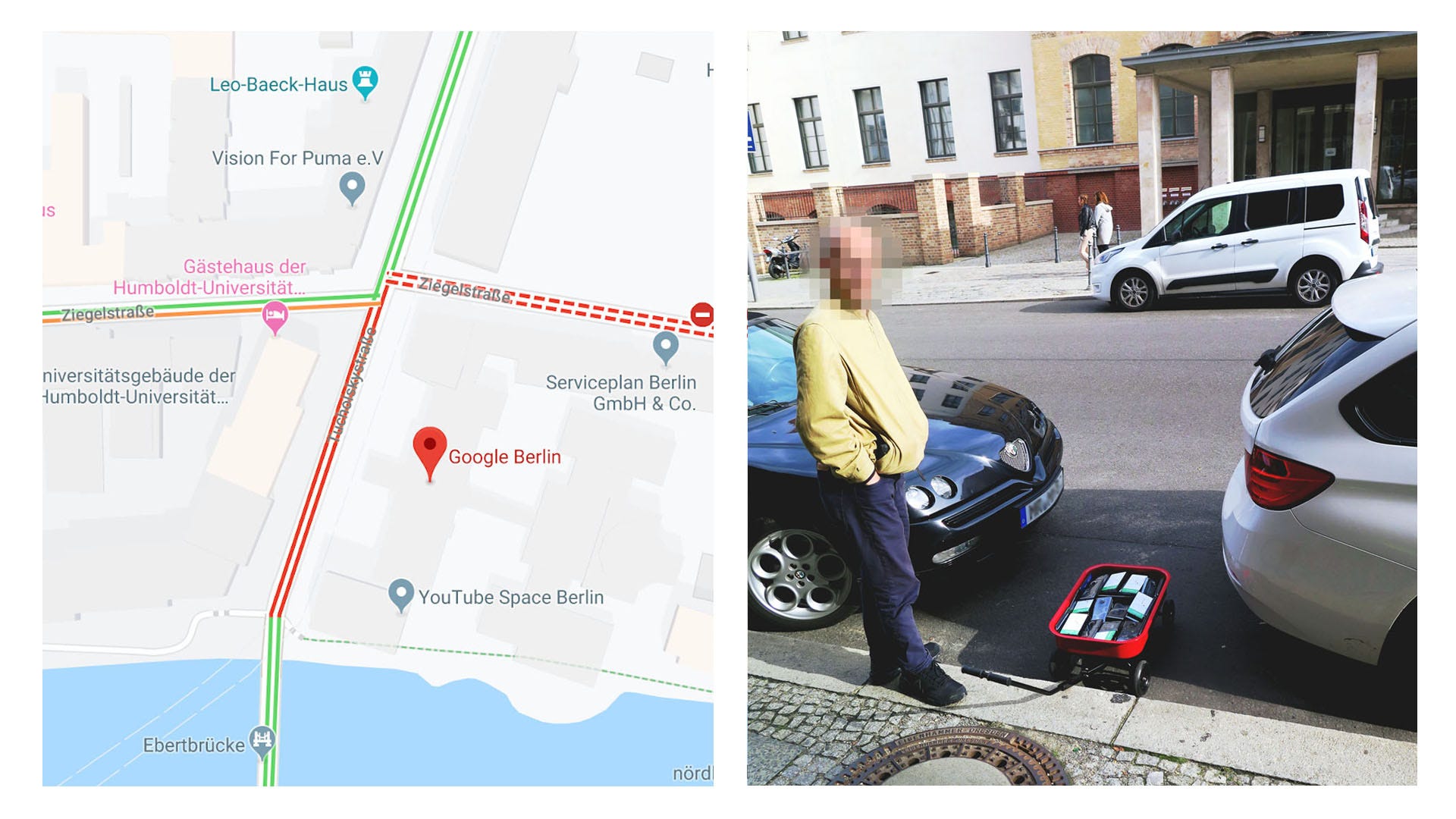
This is what Simon Weckert showed with this Google Maps hacked:
99 second hand smartphones are transported in a handcart to generate virtual traffic jam in Google Maps.Through this activity, it is possible to turn a green street red which has an impact in the physical world by navigating cars on another route to avoid being stuck in traffic.
This is sometimes often overlooked. Did you check how the data you're manipulating every day has been generated? How many choices have been made between the actual user action and the actual data point exposed?
I recently did a code analysis at work, and I wasn't surprised to see the complexity behind the data I used to query in BigQuery.
This post reminds us that, for what it's worth, data is just data. It's not reality. We should keep that in mind whenever we make decisions based on data. We should always double-check facts. Looking for drifts between the past reality and the new one.
Things are a bit rushy here; but in the good sense!
Many projects - personal and professional ones. Many new learning I can't wait to apply.
Hope you're doing well on your side :)
See you soon 👋
the team acknowledge it 😅: "Writing a Beam pipeline can be a daunting task. Learning the Beam model, downloading dependencies for the SDK language of choice, debugging the pipeline, and maintaining the pipeline code is a lot of overhead for users who want to write a simple to intermediate data processing pipeline. There have been strides in making the SDK’s entry points easier, but for many, it is still a long way from being a painless process."