


Doing house chores is always long and boring.
We tend to procrastinate rather than wash the dishes or change the bedsheets.
Finally, we do what we have to do but it often feels like an obligation rather than a pleasant moment.
Since I clean up by myself, I developed a mind toward cleaning that helps me a lot to move forward and actually clean my house. Here are some tricks :
👉 As Bill Gates said, washing the dishes can be a very thoughtful moment. Like under the shower, your mind wanders between ideas - your unconscious wakes up though you are not dreaming.
It helps to relax and live the present moment. When you actually finish the last spoon1 you have this reward to have done something useful for your future self. Weird but I often think about the last washing dish session when grabbing a fresh clean fork. It's a kind of reinforcing loop.
Don't forget: your future self is watching you right now through your memories.
👉 Before using the vacuum or the lawnmower, I try to prepare all I can to facilitate my job. Tidy. Think about the optimal path. The best steps to follow.
👉 Each time I find something new to test or optimize. It brings a sensation of novelty in something very repetitive.
👉 Always try to optimize the more I can. That way I'm more efficient with each new cleaning session as my moves are always the same. Like in a training.
There are a lot more things to do to improve and enjoy clean up.
Thinking of it as an engineering process - as a problem to solve - helps me to brave the boringness task of weekly routines.
I also try to use the best tool and guidelines to make things easier. Using gloves to clean toilets. Thinking about buying a Vapodil2. Replace sponges more often. Buy a Dyson-like vacuum. Make my own products (soap, washing powder, etc..).
Like any engineering process: if you have good organization and tools, you can succeed in your mission. Even better: you can enjoy the process.
📡 Expected Contents
Federated Learning: Collaborative Machine Learning without Centralized Training Data
This kind of blog post reminds me how far Google is. Federated Learning allows machine learning to train models on user devices and share actual learnings to others within a "shared model".
It works like this: your device downloads the current model, improves it by learning from data on your phone, and then summarizes the changes as a small focused update. Only this update to the model is sent to the cloud, using encrypted communication, where it is immediately averaged with other user updates to improve the shared model. All the training data remains on your device, and no individual updates are stored in the cloud.

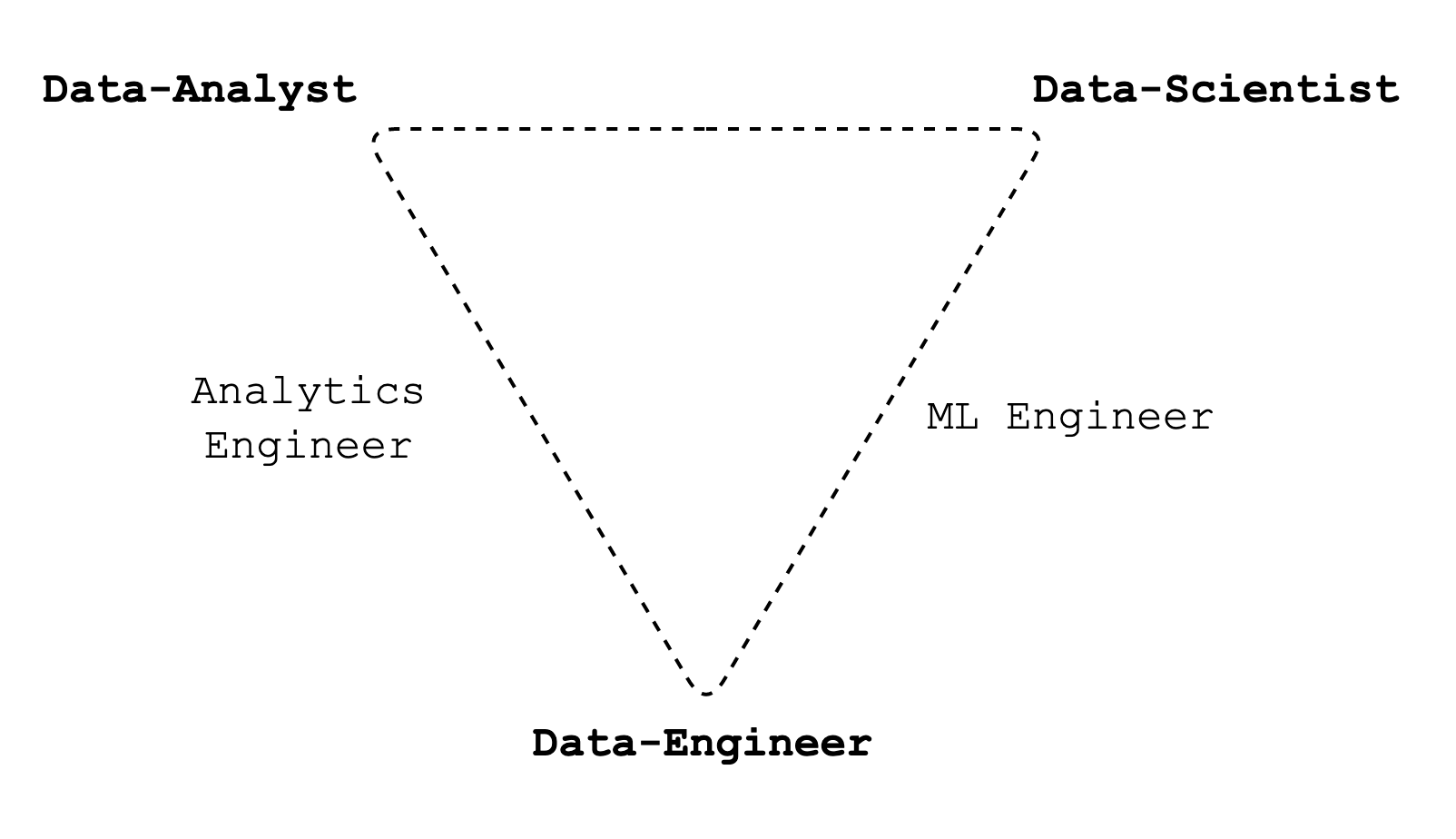
On the full-stack data science generalist
I often ask myself if I would prefer to specialize in one wing of the data stack. Since I'm working in companies, I always worked across the data-scientist and the data-engineer role - even the data-analyst sometimes.
👉 This great post from Stitch Fix explains why overwhelming specialization is not optimal, and that being generalist has many advantages.
There is further downside to functional specialization. It can lead to loss of accountability and passion from the workers. Smith himself criticizes the division of labor, suggesting that it leads to the dulling of talent—that workers become ignorant and insular as their roles are confined to a few repetitive tasks.6 While specialization may provide process efficiencies it is less likely to inspire workers.
By contrast, generalist roles provide all the things that drive job satisfaction: autonomy, mastery, and purpose.7 Autonomy in that they are not dependent on someone else for success. Mastery in that they know the business capability from end-to-end. And, purpose in that they have a direct connection to the impact on the business they’re making. If we succeed in getting people to be passionate about their work and making a big impact on the company, then the rest falls into place naturally.
Climate disaster & generation effect
The climate disaster is here. Nothing new.
👉 The Guardian released another great piece of data visualization to show how Earth will be more unlivable than it's already today.

In 2050 the millennial and X/Y generations will be in charge of the world (by 2050 all people born between 1990 to 2010 will have more than 40 years old). It might be too late to change our effect on the Earth's climate. However, this shift of power from one generation to another will probably have a huge effect on human culture and concepts.
The Web 3.0, 4 days of work shift, cryptos, NFT, metaverse, etc... Those unmatured concepts will be affined, developed, and used by this new generation.
When they'll do, changes should be real.
What happened to Facebook?
I don't know if it's a confirmation bias, but the networking issue at Facebook recently reminded me how many times we got outage problems on the Internet this year.
The internet is basically just a bunch of cables, but our web browser rarely fails to deliver content. It's always a bit strange when it's down.
I don't know that much about DNS, BGP, and all that networking stuff (still wondering what a VPC is...).
Our lives are dominated by software, but we don’t understand it very well: this is the great Justin Gage's Substack outline. He recently wrote a basic explainer of what that outage was all about.

Understanding Variational Autoencoders
These few months, I'm wondering how variational autoencoders (VAEs) can be used for simulation purposes.
Autoencoders are meant to compress the input information into a latent space (encode) to reconstruct it as accurately as possible (decode).
Due to overfitting3, the latent space of an autoencoder can be extremely irregular (close points in latent space can give very different decoded data, some points of the latent space can give meaningless content once decoded, …) and, so, we can’t really define a generative process that simply consists to sample a point from the latent space and make it go through the decoder to get a new data.
Variational autoencoders (VAEs) are autoencoders that tackle the problem of the latent space irregularity by making the encoder return distribution over the latent space instead of a single point and by adding in the loss function a regularisation term over that returned distribution in order to ensure a better organization of the latent space.
TL;DR;
VAE can be used to generate data. Synthetic data. Simulated data.
👉 Check out this great post to better understand what are VAEs!

📰 The Blog Post
Data Visualization Before Machine Learning

🎨 Beyond The Bracket

Jurassic Park is real now: with a 99.6% genetic match in the Asian elephant, intact Mammoth DNA, and modern genetic engineering, bringing back the Woolly Mammoth is well underway.
Anything is possible. 🐘.

Last month I got my first referral subscriber on Medium. It was a bit surprising while I didn't share any link. So today I am ;).
If you have ever wondered to subscribe to Medium membership here is my referral membership link:
Through this link, you both get the opportunity to access unlimited Medium content and support my writings on the platform :)
I personally use Medium as my first source of reading. More than the content, I really believe its business models make the web a better place. It let people choose to pay with money instead of attention (ads).
👉 Substack wrote a great post on that vision too.
People will hate-read and doom-scroll, but they won’t hate-pay or doom-subscribe. While people pay attention to content that makes them agitated, they’ll only pay money for content they trust and value. With this kind of model, free content can still exist, but it will be truly free — not masquerading as such while quietly extracting costs in the form of personal data or manipulated behavior. The profit driver is no longer exploiting emotions, but fostering trusting relationships between the people who create content and the people who consume it.
Have a good Christmas holiday. See you in 2022 🎉
Always ends with forks, knives, and spoons: easy things for the end.
Vapodil is a professional tool used in hotels.
An autoencoder tries to lose a minimal quantity of information during the encoding-decoding process (training by gradient descent iterations with the goal to reduce the reconstruction error)